February 2010
This is the second in a series of newsletters designed to introduce experimental design techniques. In this newsletter, we will:
- Review of Part 1
- Demonstrate how to estimate the process variation
- Show how to determine if effects are significant
- Graph the results
- Learn how to use design tables to calculate effects and interaction
- Look ahead
- Quick Links
The experimental design techniques we are examining are two-level full factorial designs. The newsletter series will show you how to plan, conduct and analyze these two level designs. A manual method of analyzing the results is given. This manual method provides clear method of understanding what an effect is, what a main effect is and what an interaction between factors is. We will use ANOVA (analysis of variance) in a later newsletter to analyze experimental design results. This is the most common way of examining the results of an experimental design with software that is available today.
Review of Part 1
You can read the first part at this link: part 1. In this first newsletter, we introduced the process we are using as an example of a two-level full factorial design. This process involves a stirred batch reactor. Your product is a chemical and the purity of that chemical is critical to customers. You would like to improve the chemical’s purity. There are two process variables that you think impact the purity: the reactor temperature and the residence time of the chemical in the reactor. How do you find out the following?
- Do the reactor temperature and/or residence time impact the average purity?
- If so, by how much? For example, if I change the reactor temperature 5 degrees, what is the impact on the average purity?
- Do the reactor temperature and/or residence time impact the variation in the purity?
- If so, by how much? For example, if I increase the residence time in the reactor by 10 minutes, do the purity results have more variation?
We then introduced some experimental design terminology including:
- Factors (fixed and random, qualitative and quantitative)
- Levels of factors
- Response (discrete and continuous)
- Treatment combinations
- Replication
- Experimental error
- Effects
- Main effects
- Interaction between factors
We then introduced our design layout for this two factor example and the data our experimental design generated. These are shown in the two tables below.
Experimental Design Layout
| Residence Time | Temperature | |
| t0 = 50°C | t1 = 90°C | |
| r0 = 30 minutes | Cell 1 | Cell 2 |
| (Three runs) | (Three runs) | |
| r1 = 90 minutes | Cell 3 | Cell 4 |
| (Three runs) | (Three runs) | |
| Run | Rx. Temp. | Res. Time | % Purity | Average | Range | ||
| 1 | 50 | 30 | 74 | 78 | 73 | 75 | 5 |
| 2 | 90 | 30 | 65 | 64 | 69 | 66 | 5 |
| 3 | 50 | 90 | 74 | 76 | 78 | 76 | 4 |
| 4 | 90 | 90 | 85 | 88 | 91 | 88 | 6 |
In our experiment, residence time and temperature are both fixed factors. The levels of residence time are 30 minutes and 90 minutes. The levels of temperature are 50°C and 90°C. The product purity is a continuous response variable. There are three runs at each treatment combination. We used the data to calculate the effects of each factor and interaction. We have determined the following so far:
- Main Effect of Temperature = 1.5
- Main Effect of Residence Time = 11.5
- Interaction between Temperature and Residence Time = 10.5
A main effect is defined as the difference between the results when a factor is at its high level and when a factor is at its low level. Thus, purity is 1.5 higher at the high level of temperature than at the low level of temperature; it is 11.5 higher at the high level of residence time than at the low level of residence time.
The main effect describes how a factor influences a product response. This influence, however, sometimes depends on the levels of the other factors. This is called interaction. In this example, the interaction between temperature and residence time is 10.5
Are these numbers significant? If a factor does not have an effect on a product response, one would expect the main effect or interaction to be zero. Of course, with normal process variation, the main effect or interaction will not be zero. For a main effect or interaction to be statistically significant, it must be significantly different from zero. This month’s newsletter describes how to determine if these main effects or interaction are statistically significant.
Estimating Process Variation
So, the question is “are the main effects or interactions significant?” The answer is that it depends on the process variation. Replicating each treatment combination provides an estimate of the process variation. This estimate will be used to determine a confidence interval around the effect. If the interval contains zero, the effect is not significant. If it does not contain zero, the effect is significant.
The process variation must be estimated first. The range values for the replication are used to determine the variability in the process. The average range is determined using the formula below:
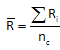
where Rbar is the average range, Ri is the range of responses in cell i and nc is the number of cells. The standard deviation, s, is estimated from the average range using the same equation used for the Xbar -R chart:
![]()
where s is the estimated standard deviation and d2 is the control chart constant that depends on subgroup size (in this case, the number of replications in each cell). Using the range values in the table above, the average range and estimated standard deviation are calculated as shown below using d2 = 1.693 for n =3.
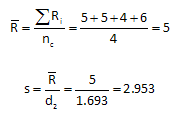
This approach assumes that the variation between all cells is the same. This assumption can be checked by constructing a range chart. The control limits for the range chart are given by:
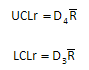
where D4 and D3 are control charts constant that depend on the subgroup size. For this example, the control limits are calculated as shown below using D4 = 2.574 and D3 = none for n = 3:
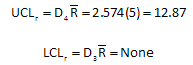
Since none of the range values are above 12.87, we conclude that the variation within each cell is the same and this variation is represented by s = 2.953.
Determining if Effects are Significant
This process variation will be used to determine if each effect is significant. Each effect is the difference between two averages. The t distribution is used to determine if there is a significant difference between two averages. The confidence interval for the difference in two averages is given by:
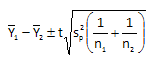
sp2 is the pooled variance. For the experimental design, this pooled variance is the same as s2. Thus, the above equation can be rewritten as:
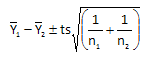
The factorial design we are discussing is a balance design, i.e., the same number of runs are made at each corner of the factor space. Thus, n1 = n2 = mk where m = number of cells at each level of the factors and k is the number of replicates. Thus,
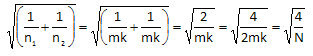
where N = 2mk is the total number of factorial observations (experimental runs). Using this, the confidence interval for the difference in averages becomes:
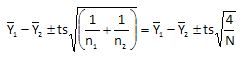
We can define a term we call the Minimum Significant Effect (MSE). This is given by:
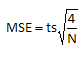
The difference in two averages is then given by:
![]()
To calculate the value of MSE, we must know s, N and t. We already know that s = 2.953. N is the total number of experimental runs at the corners of the factor space. For this example, N = 12 (three runs at each corner of the square). To determine the value of t, a confidence coefficient must be selected and the degrees of freedom determined. For 95% confidence, alpha = 0.05. The degrees of freedom is the degrees of freedom used to calculate the standard deviation. It is given by:
Thus, df = 12 – 4 = 8. For alpha = 0.05 and df = 8, the value of t is 2.306. This can be found in a table for the t distribution that is available in many statistical books or by searching for a t distribution table on-line. In Excel, you can find this value by using the TINV function.
Thus, the value of MSE is:
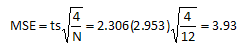
Using MSE, a confidence interval can be set up around each effect and interaction. Thus,
Effect of temperature: 1.5 ± MSE = 1.5 ± 3.93 = [-2.43, 5.43]
Effect of residence time:11.5 ± MSE = 11.5 ± 3.93 = [7.57, 15.43]
Interaction of temperature and residence time:
10.5 ± MSE = 10.5 ± 3.93 = [6.57, 14.43]
The confidence interval for the effect of temperature contains zero. This means there is not a significant difference between the average effect when temperature is at it high level and when temperature is at its low level. The confidence intervals for the effect of residence time and the interaction term do not contain zero. For residence time, this means there is a significant difference in the results between the runs when residence time is at its high level and the runs when residence time is at its low level. In addition, since the interaction term is significant, this means that the effect that residence time has on purity depends on the level of temperature.
It should be noted that you do not have to construct the confidence interval. If the absolute value of an effect is greater than MSE, the effect is significant since the interval will not contain zero.
Graphing the Results
The analysis above shows that the effect of residence time is significant while the effect of temperature is not significant. However, the interaction between residence time and temperature is significant. This means the level that temperature has does impact the results. This can be seen be graphing the results as shown below.
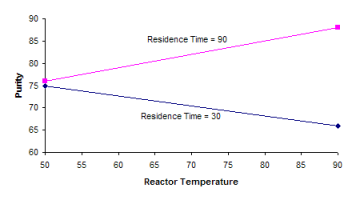
When residence time is at its low level (30), the purity decreases as temperature increases. However, when residence time is at its high level (90), the purity increase as temperature increases. Thus, there is a strong interaction between temperature and residence time.
It is easy to see from this graph that, if you want to maximize purity, you would set the process to operate at the high level of temperature (90) and the high level of residence time (90).
Using Design Tables to Calculate Effects
Effects and interactions can also be calculated using design tables. To understand how to set up a design table, we will use “coded” factor levels. When a factor is at its low level, it is represented by a -1. When a factor is at is high level, it is represented by a +1. This situation is shown in the figure below.
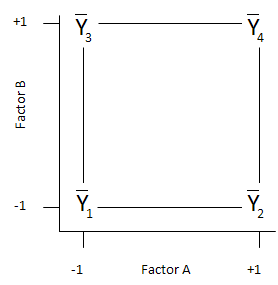
The numbering of the cells (1 through 4) is a standard numbering system (called Yates’ run order) used in experimental designs. The design table for our two factor example is given below using Factor A for temperature and Factor B for residence time.
| Run | Mean | A | B | AB |
| 1 | + | – | – | + |
| 2 | + | + | – | – |
| 3 | + | – | + | – |
| 4 | + | + | + | + |
The mean column will be explained later. For run 1, both factors are at their low level (-1). Thus under A and under B, a – sign is placed (the 1 is dropped for convenience). The sign under AB is determined by multiplying the level of A by the level of B, i.e., (-1)(-1) = +1. Thus, a + sign is placed under the AB column for Run 1. The same approach is used for Runs 2 – 4.
This design table can be used to determine the effects and interactions. This is demonstrated in the table below.
| Run | Mean | A | B | AB | Average |
| 1 | + | – | – | + | 75 |
| 2 | + | + | – | – | 66 |
| 3 | + | – | + | – | 76 |
| 4 | + | + | + | + | 88 |
| SPlus | 305 | 154 | 164 | 163 | |
| SMinus | 0 | 151 | 141 | 142 | |
| Overall | 305 | 305 | 305 | 305 | |
| Difference | 305 | 3 | 23 | 21 | |
| Effect | 76.25 | 1.5 | 11.5 | 10.5 |
To determine the values in the table:
- Enter the average response for each run under “Average.”
- Sum the average responses with + signs and enter the result in the row SPlus for each column.
- Sum the average responses with – signs and enter the result in the row SMinus for each column.
- Add SPlus and SMinus together and enter the result in the overall row for each column. This should be the same for each column.
- For each column, subtract SMinus from SPlus and enter the result in the difference row.
- Divide the difference by the number of + signs under the column to determine the effect.
For example, Runs 2 and 4 have + signs for Factor A. Adding the average responses for these two runs gives:
SPlus = 66 + 88 = 154
Runs 1 and 3 have – signs for Factor A. Adding the average responses for these two runs gives:
SMinus = 75.0 + 76 = 151
To obtain the number for the Overall column, add these two together:
SPlus + SMinus = 154+ 151 = 305
The Overall column represents a check on the math. This should be the same for all columns. To determine the Difference number, subtract SMinus from SPlus:
SPlus – SMinus = 154 – 151 = 3
Then to determine the effect number, divide this difference by the number of plus signs:
Effect = 3/2 = 1.5
The same procedure is used to determine the effects under columns B and AB. These effects are then compared to MSE to determine if there are significant. If the absolute value of an effect is larger than MSE, the effect has a significant affect on the response variable.
The mean column has all + signs under. The “effect” under the mean column is the average response for the all the experimental runs. Remember that to determine the effect, the difference is divided by the number of + signs in the column. For the mean column, there are four + signs.
Looking Ahead
You can use this design table to analyze any two-level factorial design, regardless of the number of factors. Next month we will continue our examination of full factorial designs. We will look at how to develop a model for the response based on the factors, how to use ANOVA to analyze the results, and extend this process to designs with more than two factors. The following month we will take a look at how these techniques are used in the pharmaceutical industry.